
Invinite at the Finnish Health Data Hackathon 2026: Data as Software in Practice
In January 2026, Invinite participated in the Finnish Health Data Hackathon. We joined the Care Plans track focused on testing, where we explored whether a Data as Software (DaS) approach could be used for testing and validating synthetic FHIR data both structurally and in terms of how realistic the data is.
The core idea behind DaS is simple: data engineering doesn't have to be different from software engineering. The same practices that make code maintainable (types, tests, code review, CI/CD) apply directly to data transformations. It's not about replacing SQL or abandoning existing tools, but about wrapping data work in the engineering discipline that software teams take for granted.
We’ve already used DaS successfully in Lakehouse projects with Finnish wellbeing counties, where it has helped us get reliable pipelines into production. That’s why we wanted to try the same approach for building a validation pipeline for synthetic data.

Eetu Sutinen and Tommi Summanen representing Invinite at the hackathon
Why Synthetic Data Quality Matters
AI applications need representative distributions: If test data doesn’t reflect reality, you can’t validate AI-generated insights.
Research and clinical analytics need trustworthy cohorts: Synthetic data must preserve clinically meaningful patterns (for example prevalence, comorbidities, lab value ranges, and care pathways), otherwise research findings and feasibility analyses become misleading.
Performance testing requires realistic patterns: Data distribution affects query performance, partitioning strategies, and access patterns.
Compliance testing needs edge cases: Synthetic data must include the boundary conditions that trigger validation logic.
It is easy to assume synthetic data quality is mostly about generating realistic-looking records, but research shows the hard part is usually proving that the data is both safe and useful. In healthcare, synthetic datasets must balance privacy and realism, and the literature highlights anonymization and data fidelity as two fundamental concerns. Importantly, quality evaluation is described as its own step in the synthetic data lifecycle, typically covering fidelity, privacy, and downstream utility. In other words, synthetic data generation is not complete until it can be validated, and validation cannot rely on a single score or a visual inspection. (Pezoulas et al., 2024)
This is where a Data as Software approach becomes a natural fit: turn validation into typed, testable code and enforce it systematically.
Architecture: The Medallion Pattern
We follow the medallion architecture (bronze → silver → gold), but with an important design decision: only bronze and gold persist to disk.
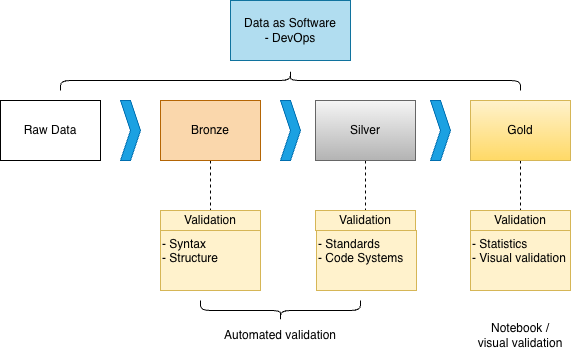
DaS Medallion Architecture
Silver runs in-memory because:
Refactoring without migrations - intermediate schemas probably change during development
No intermediate data exposure - only raw and final outputs are visible
Simpler debugging - persist silver tables only when needed
Code-First Data Quality
The core innovation is expressing data validation as typed Python code. We define typed models that are more than documentation: the DataFrame schema is validated against the type definitions at runtime.
class Observation(TypedLazyFrame):
"""Observation model - domain-modeled from FHIR Observation."""
id: Col[str]
status: Col[str]
subject_id: Col[str]
value_quantity_value: Col[float]
validation_errors: Col[list[str]]
Validation rules are declarative. Failed validations don't drop rows. They populate a validation_errors column, preserving data lineage and enabling aggregate quality reporting.
Testing Transformations Like Software
With transformations expressed as functions, we can test them with pytest like any other code. Tests execute in milliseconds because Polars lazy evaluation only materializes data when needed.
This means:
Code review catches logic errors - validation rules are reviewable Python, not buried in SQL
CI/CD validates changes - automated checks run on every commit
Refactoring is safe - type checkers and tests catch regressions
Visual Validation
For properties that are hard to express as unit tests, like distribution shapes, we use marimo notebooks. The gold layer aggregates data into metrics that can be visualized. A static export is available in this notebook demo.
Why This Matters for Healthcare
Healthcare software development faces a data paradox: you need realistic test data to build quality software, but real patient data requires strict access controls. Synthetic data bridges this gap, but only if it's actually representative.
DaS methodology provides:
Auditable quality - every validation rule is version-controlled and testable
Reproducible pipelines - same code runs anywhere (laptop, CI, cloud)
Iterative improvement - fix a validation gap, add a test, ship confidently
Explore the Code
The full source is available on GitHub: inviniteopen/fhir-hackathon
The stack includes uv, Polars, DuckDB, marimo, and pytest. All chosen for developer experience and performance.
Conclusion
The hackathon gave us a focused opportunity to demonstrate that data engineering doesn't have to be different from software engineering. The same practices that make code maintainable (types, tests, code review, CI/CD) apply directly to data transformations.
Data as Software isn't about replacing SQL or abandoning existing tools. It's about wrapping data work in the engineering discipline that software teams take for granted.
Interested in Data as Software and modern data engineering in healthcare? We’d love to connect! Let's talk.
References
Pezoulas VC, Zaridis DI, Mylona E, Androutsos C, Apostolidis K, Tachos NS, Fotiadis DI. Synthetic data generation methods in healthcare: A review on open-source tools and methods. Comput Struct Biotechnol J. 2024 Jul 9;23:2892-2910. doi: 10.1016/j.csbj.2024.07.005. PMID: 39108677; PMCID: PMC11301073.
https://www.csbj.org/article/S2001-0370(24)00239-3/fulltext